Android Gradle 编译常见优化手段
本文主要分享常见的 Gradle 编译优化手段,并提供成本,收益,推荐度等维度供参考。以帮助大家快速找到最适合自己项目情况的优化项。
文章内容介绍
每个团队或许都有那么一个或两个比较关注工程编译耗时的同学,那么这篇文章就是分享给你的。
本文主要分享常见的 Gradle 编译优化手段,并提供成本,收益,推荐度等维度供参考。以帮助大家快速找到最适合自己项目情况的优化项。
可用的编译优化观察工具
工欲善其事,必先利其器。本章节介绍可以让你观测编译情况的工具。
Gradle Build Scan
Gradle Build Scan 是分析编译耗时不得不了解的一个官方工具。它提供了几乎所有你想了解的信息:
-
编译耗时
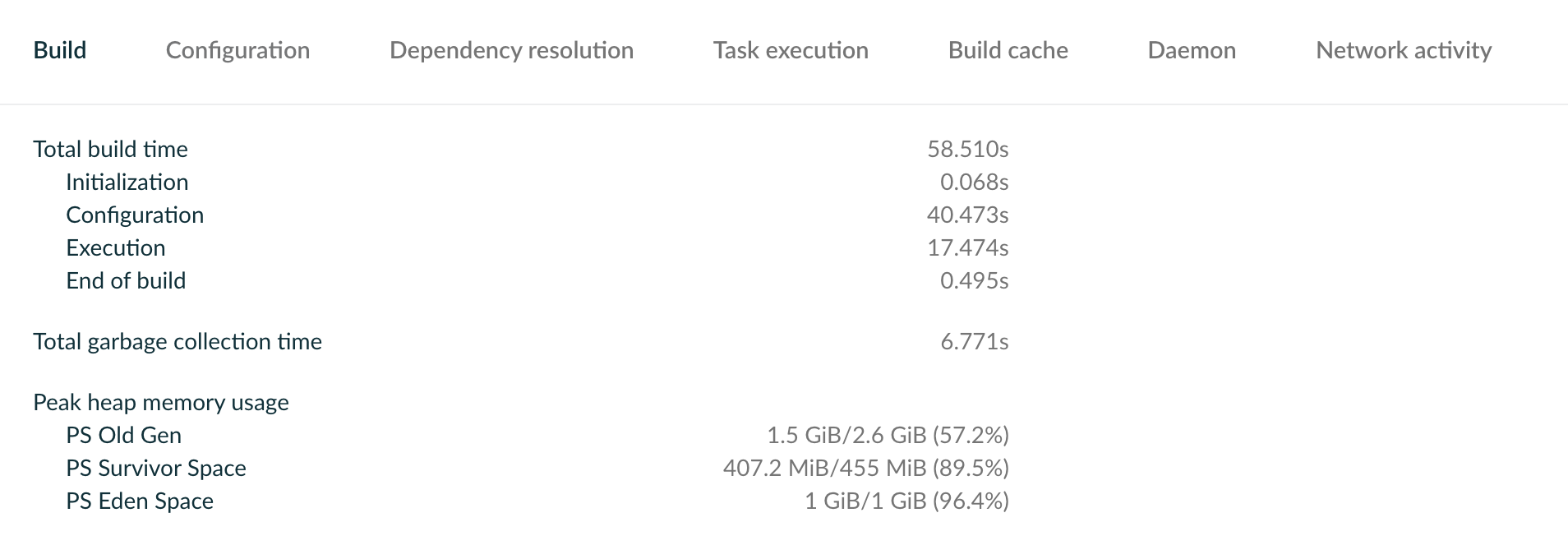
-
task 实现,task 的前后依赖关系

-
task 缓存命中情况
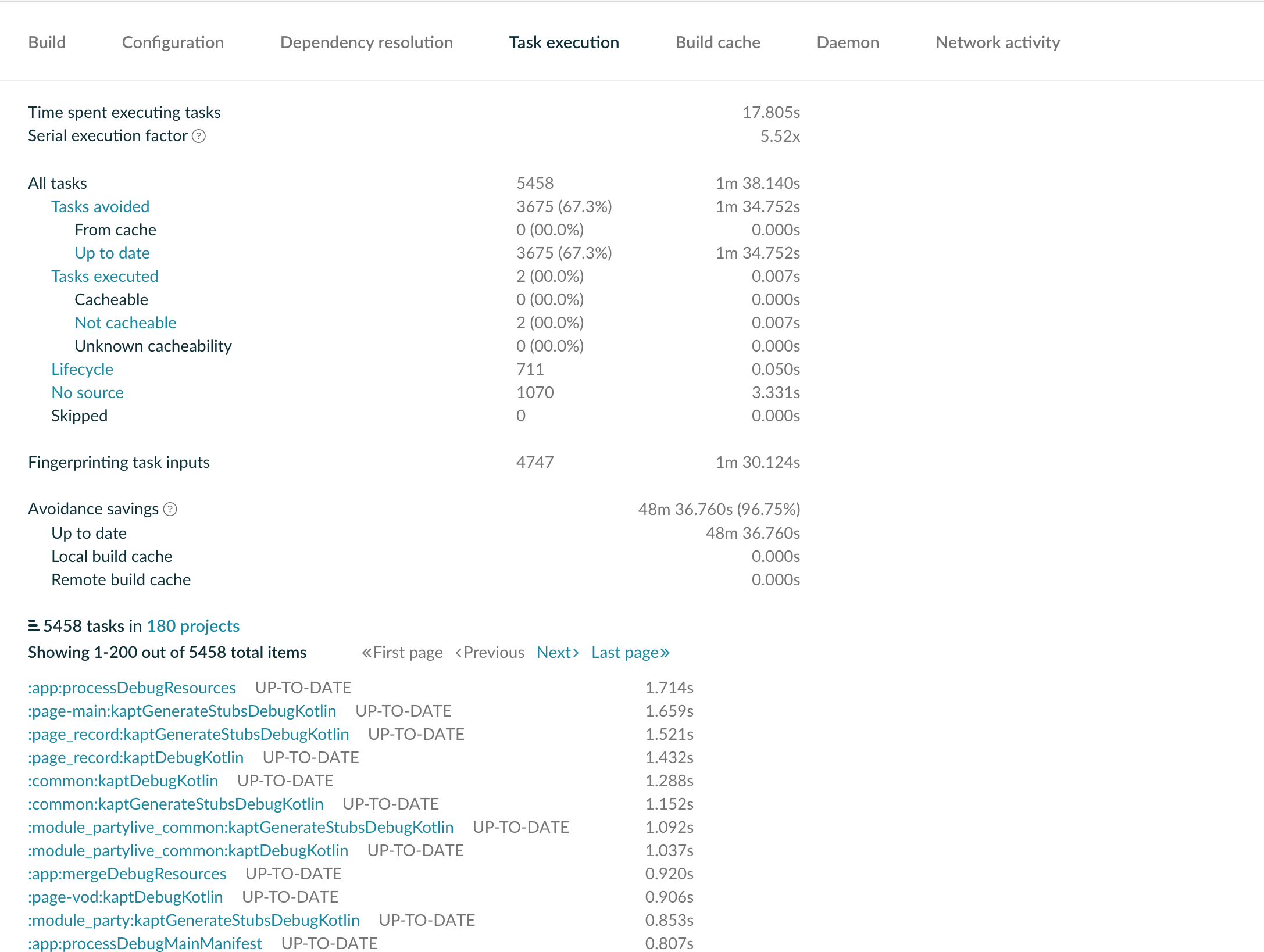
-
task 执行时间线
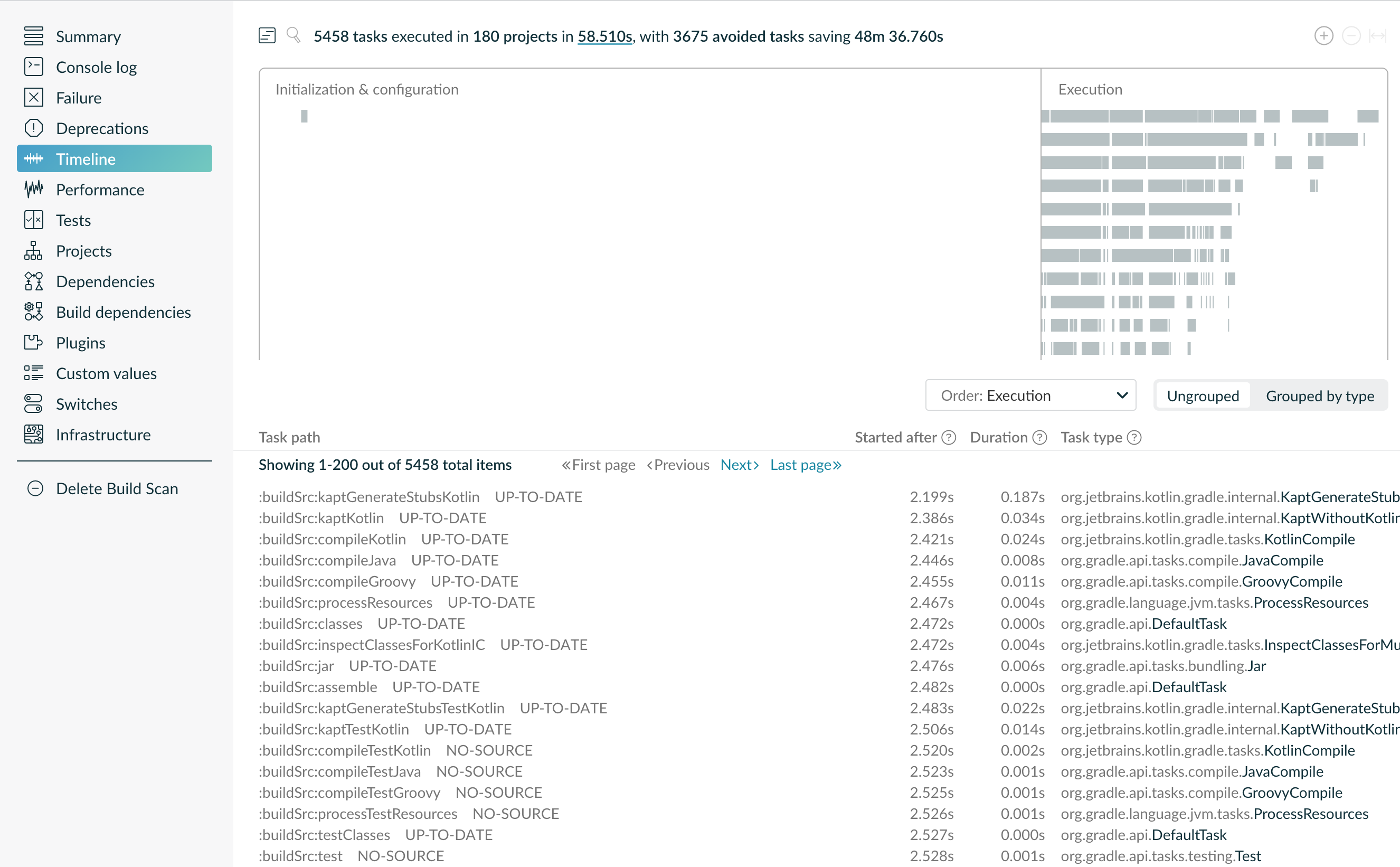
-
两个 gradle 执行对比,可用于对比两个构建之间无法复用缓存的 task 究竟是什么参数不同导致。这个功能最近收费了,可恶啊

如何使用
方式一:gradle 命令末尾加上 --scan 参数
方式二:在工程根目录 settings.gradle 增加如下声明:
apply plugin: com.gradle.enterprise.gradleplugin.GradleEnterprisePlugin
gradleEnterprise {
buildScan {
termsOfServiceUrl = "https://gradle.com/terms-of-service"
termsOfServiceAgree = "yes"
// isOpenDebugLog 控制是否开启默认发布scan链接
publishAlwaysIf(isOpenDebugLog)
}
}
项目编译数据分享
在不同的时间段,我对产品的主工程编译进行了集中投入优化,效果还不错:
编译耗时中位数 1.5min -> 0.5min(中位数可以比较好的体现增量编译的耗时): 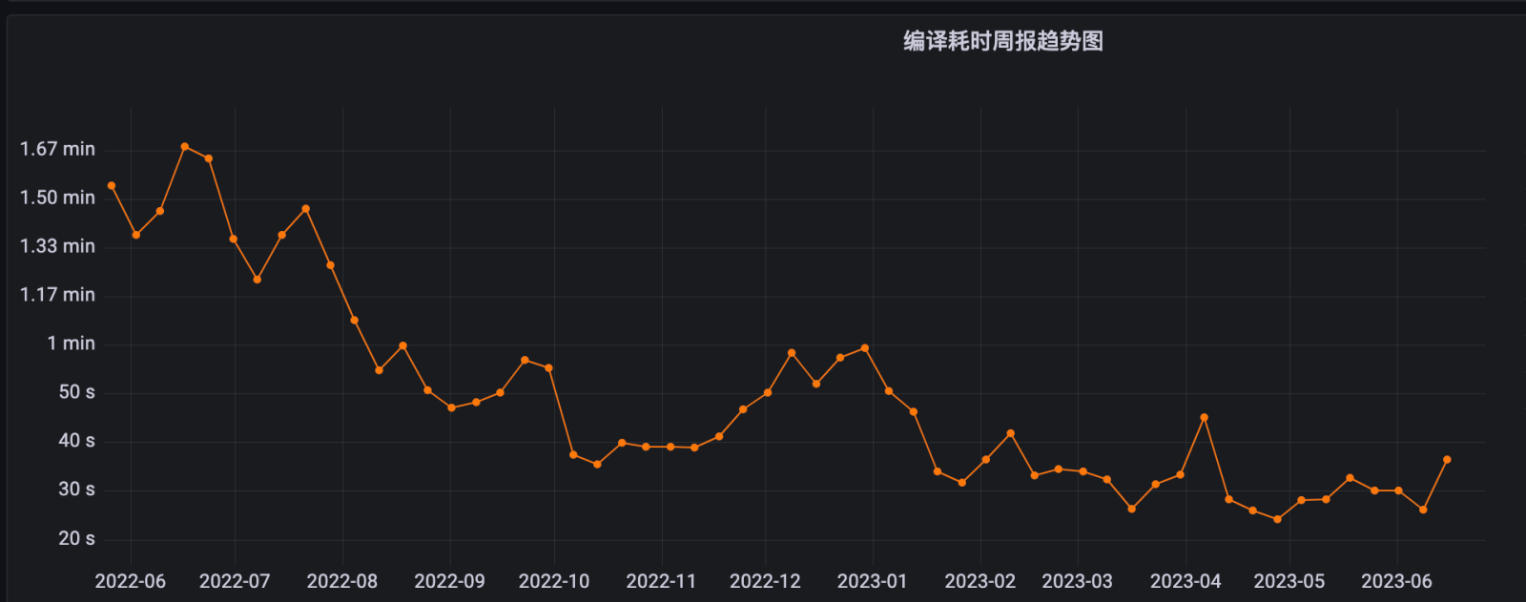
编译平均耗时 2.5min -> 1.6min(本地): 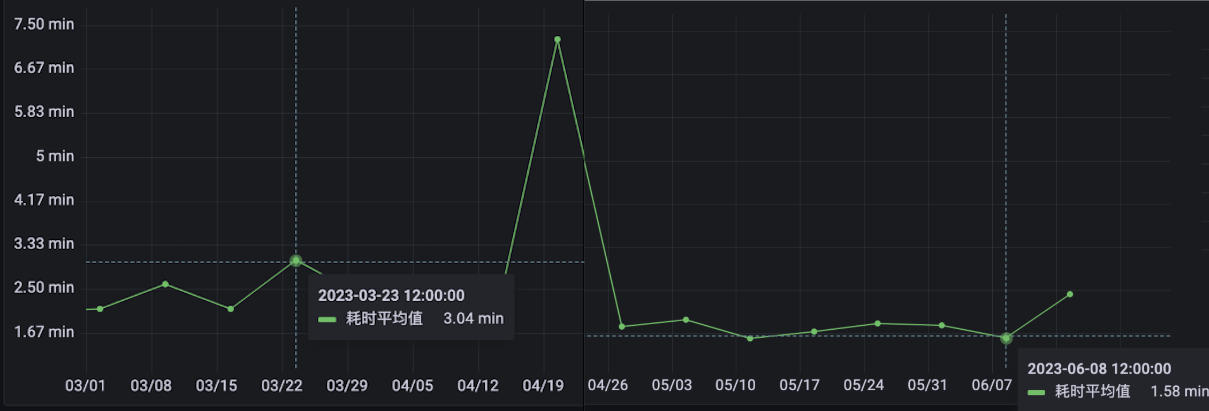
编译平均耗时 5.4min -> 4.1min (蓝盾): 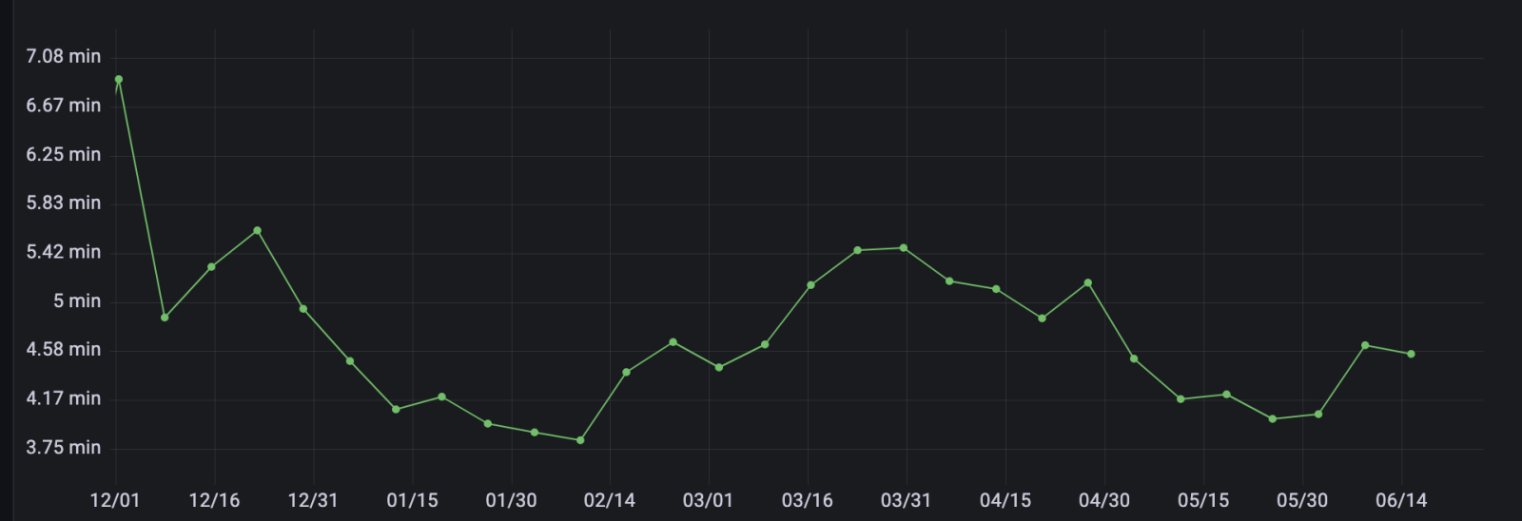
当然,项目是不断在增长和劣化的,停止优化后编译耗时又会开始缓慢上涨。
可行的优化项
1. 云编译——真正的工程学
电脑很卡,那就换台电脑。——鲁迅
这里云构建指的是:购买云开发机,通过 ssh 和 rsync 工具完成源码推送,编译,产物拉取。
Sickworm 锐评
- 收益:大
- 成本:小,一次配置,终身受用(配置耗时 1 小时左右)。
- 综合推荐度:?????
2. Gradle task 执行优化 —— 让你的 task UP-TO-DATE,不用每次都执行
在漫长的代码提交过程中,会有各种各样的人因为各种各样的需求,往工程里面增加各种各样的 task。
但并不是每个人都擅长将一个 task 写的高效,很容易就让编译耗时逐渐劣化。比较常见的,就是写了一个每次都需要执行的耗时 task。
Gradle task 的执行结果大部分情况是这三种:(你可以通过 gradle 运行时输出和 build scan 来观察 task 的执行结果)
- EXECUTED:正常执行
- UP_TO_DATE:实现和输入都没有变化,依赖的 task 也没有执行,且输出产物没有被删除,无需重复执行。
- FROM_CACHE:task 输入在 gradle cache 中找到了缓存,从缓存中获取。
更多的类型见:Authoring Tasks
不带任何声明直接实现一个 task,执行结果将每次都是 EXECUTED。 如果需要让 task 在第二次执行变为 UP_TO_DATE,其中一个必要条件是:需要将所有的入参和出参都用 @Input @Output 等注解声明,以此告诉 Gradle 如何正确地保证 task 按需执行。
所以这同样也有一个弊处:不正确地声明输入输出,可能导致 task 该执行的时候没执行,出现预期相反的情况。
如何实现一个正确的增量编译 task,可参考官方介绍:Incremental build
Sickworm 锐评
- 收益:大
- 成本:大
- 综合推荐度:?????(Gradle 编译优化必须懂得的概念)
3. Gradle task 执行优化 —— 不必要的 task 不要执行
在漫长的代码提交过程中,会有各种各样的人因为各种各样的需求,往工程里面增加各种各样的 task。(复读机)
但并不是每个人都会细致的思考:我这个 task 是否所有人都需要?是否每次构建都需要? 久而久之,就会出现不少平时编译调试并不需要的 task,但每次都花费大家不少的执行耗时。
对于本地开发编译,这里有几个建议可以参考:
-
多做开关,保持本地开发纯洁。比如特殊场景的 task,如上传,参数校验等,是否可以仅需要时才执行?
-
尽量不要在本地开发阶段引入插桩。插桩真的非常耗时,而且很容易扩散,使依赖 task 的缓存失效。
-
BuildConfig 尽量不要引入每次都会变化的变量,如构建时间,commit hash。这会导致编译 task 每次都要执行。
-
其余的 task,根据 build scan 的扫描结果,找到不必要的耗时 task,尝试按需执行。
Sickworm 锐评
- 收益:大
- 成本:中
- 综合推荐度:?????(是一个需要持续关注并投入的活儿)
4. Gradle 本地 task cache —— 让你的 task FROM-CACHE,让缓存跨工程复用
上文提到 task 常见的三种执行结果:EXECUTED,UP-TO-DATE,FROM-CACHE,其中 FROM-CACHE 就是命中缓存的结果。
命中缓存和 UP-TO-DATE 的判断条件几乎一致,差异是:
- task 需要通过注解
@CacheableTask来声明自己可以缓存; - task 输出产物不存在,但在 gradle build cache 里面找到了。
build cache 为何物
build cache 是 Gradle 自带的一个 task 缓存能力。打开方式:在 gradle.properties 声明 org.gradle.caching=true,打开后默认启用本地缓存。
build cache 的缓存是如何命中的
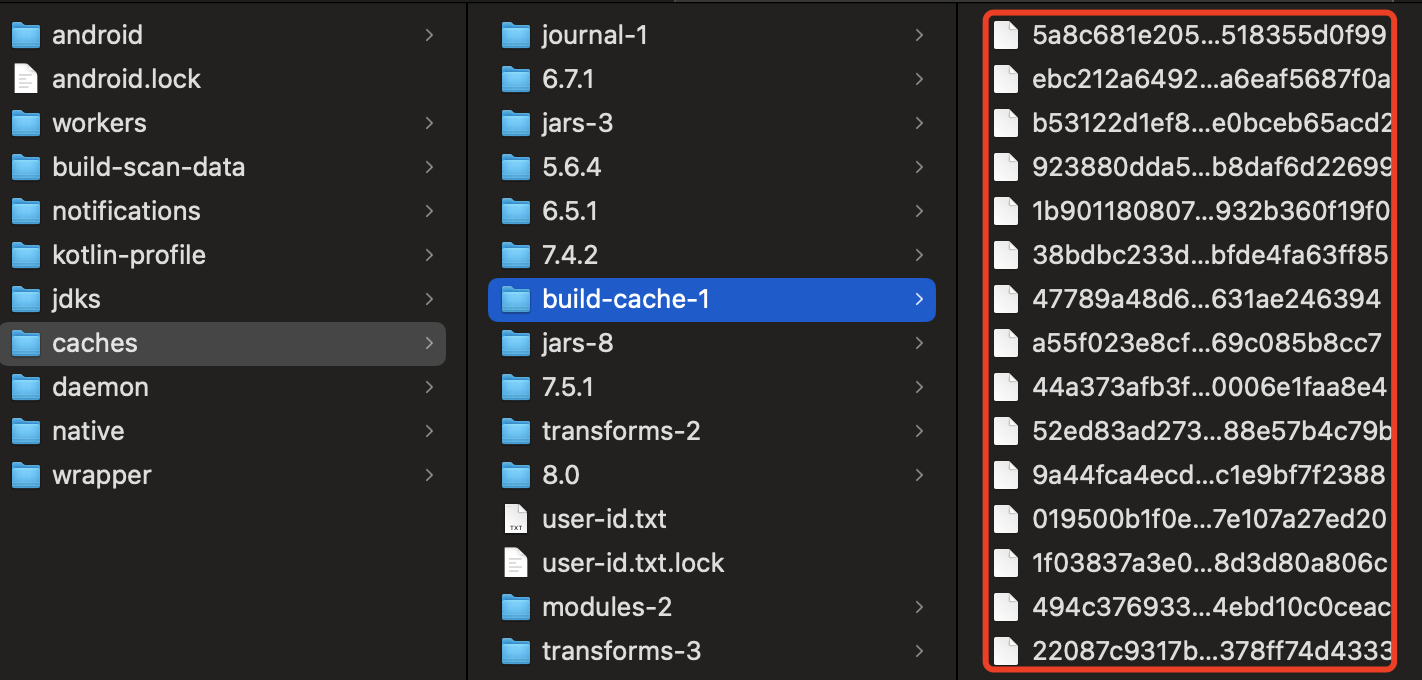
所有可能影响 task 的变量,包括但不限于所有入参,task 实现,buildSrc 源码,gradle 版本,JVM 版本,都会被加入计算,得到一个 string 类型的 cache key。通过 cache key 可以快速比对是否有命中的缓存。build-cache 最终会存储到这里:
和 UP-TO-DATE 的问题一样,如果没有正确实现入参出参声明,则可能出现 cache 不正确被复用的情况。
目前大部分 Gradle 和 AGP task 都已经正确实现入参出参声明和声明可缓存。之前开发还会偶尔出现脏 cache 的情况,需要 clean + 关闭 cahce。但升级为 gradle 7.3.3 + AGP 7.2.2 之后,我个人就没遇到过了。
同事倒是经常说遇到,但没有证据。(编译信任是一件很难的事)
官方介绍:Build cache
使用场景
正常情况下,本地 build cache 只在工程删除了产物的时候能够用上。如果是多工程场景,如我们可能在一个工程上同时开发多个需求,我们可能就会同时有这个工程的多份拷贝。这个时候如果两个工程代码相似,则在这个工程编译完成后,另一个工程有机会复用部分 task 缓存,节省编译时间。
但看起来好像还是挺鸡肋的~其实 build cache 真正的杀器是远程 build cache,见下节。
Sickworm 锐评
- 收益:小
- 成本:大(缓存复用是门大学问)
- 综合推荐度:??(只做本地缓存用处不大,真正给力还得看远程 cache)
5. Gradle task 远程 build cache —— 让 CI 构建的缓存可以被开发机复用
Gradle 支持指定远程 build cache。这样一来,task 缓存就可以跨设备共享了。比较典型的做法是,由 CI 构建编译并上传 build cache,本地开发机仅读取。
搭建远程 build cache 的服务器有几个选择:
- Gradle Enterprise,要钱。
- 自行搭建缓存 service:Build Cache Node User Manual
更详细的 build cache 配置方法可看官方介绍:Configure the Build Cache
如何优化缓存复用
前面提到非常多的条件可能使得 task 缓存 key 发生变化,导致无法复用缓存:
- buildSrc 变更;
- Gradle JVM 版本;
- task 实现(也就是插件版本);
- 入参,如果是 Java / Kotlin 编译 task,则可能是源码变化,BuildConfig 等自动生成的源码变化,模块依赖变化;
我们判断 task 是否成功复用缓存,可以通过以下方法检验:
- 基于某个指定 commit,在 CI 构建机上构建并上传 task 缓存;
- 本地工程执行 clean 移除本地产物,关闭本地缓存,然后基于同一个 commit 进行编译;
- 如果 task 执行结果为 FROM-CACHE,则为复用成功。
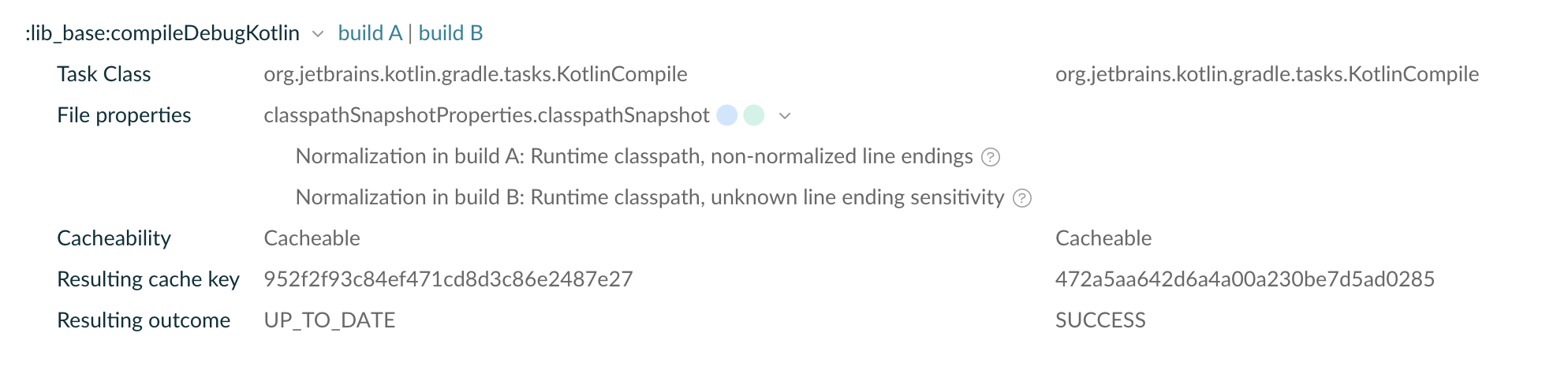
对于没有 FROM-CACHE 的 task,除了声明不支持 cache 之外的 task,我们需要分析缓存为何没有复用。最好的办法就是使用 build scan 的编译结果比较功能,他可以指出两个编译之间,为何 task 的缓存无法复用:

但目前该功能已经收费了,只能用免费的办法:编译时增加参数 -Dorg.gradle.caching.debug=true,此时 gradle 会把 cache key 的计算过程打印出来。我们拿到所有日志后,在两个编译之间再进行比对。
精华内容——你可能会遇到的缓存无法复用的原因
以下一些常见的操作可能会导致你的缓存无法复用:
-
buildSrc task 无法复用,导致绝大部分 task 都无法复用,所以首先需要保证 buildSrc 可以复用。解决方法和其他 task 解决方式一致,单独提及只是想引起大家重视。
-
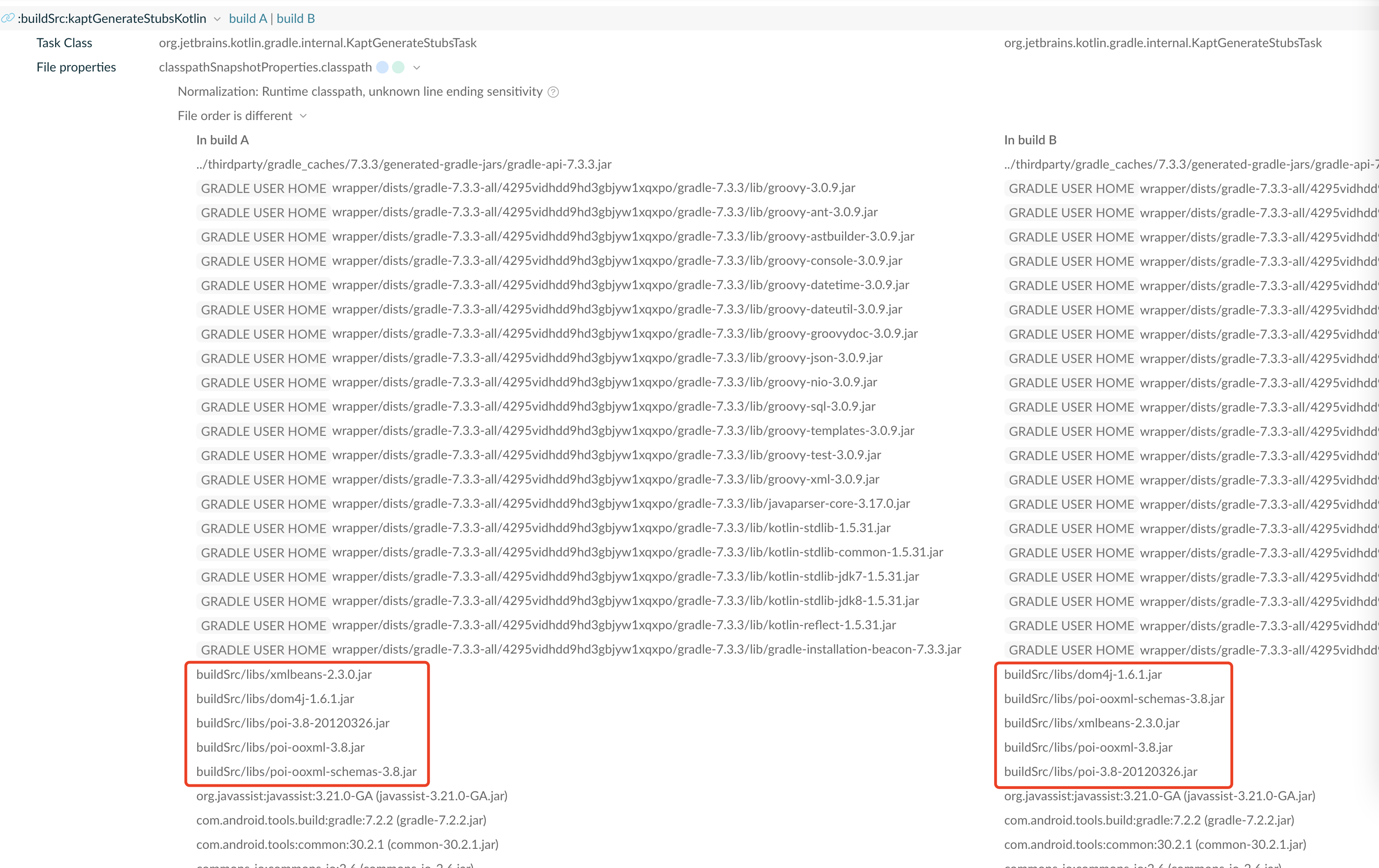
使用了
fileTree(include: ['*.jar'], dir: 'libs')导致依赖顺序不稳定。fileTree 是一个顺序不稳定的 api,需要进行排序:fileTree(include: ['*.jar'], dir: 'libs').sorted()
- 打开了
kotlin.incremental.useClasspathSnapshot=true。会导致编译产物不稳定导致无法复用 Kotlin 编译缓存,建议关闭。
-
打开了
android.enableJetifier=true。jetifier 本身是一个输出不稳定的工具,不同设备的 jetfied 结果可能和本地不一致,导致 jar md5 不一致,从而导致缓存无法复用。于是我花了不少精力,把 jetifier 关掉了(见后面内容)。 -
使用
SNAPSHOT包。由于 SNAPSHOT 包更新和实现的不确定性,会导致不同设备的依赖不完全一致。非常建议使用非 SNAPSHOT 包以提高缓存命中率。 -
声明了较多的
api依赖。API 的依赖变更,会导致所有模块需要重新编译,建议减少api依赖。 -
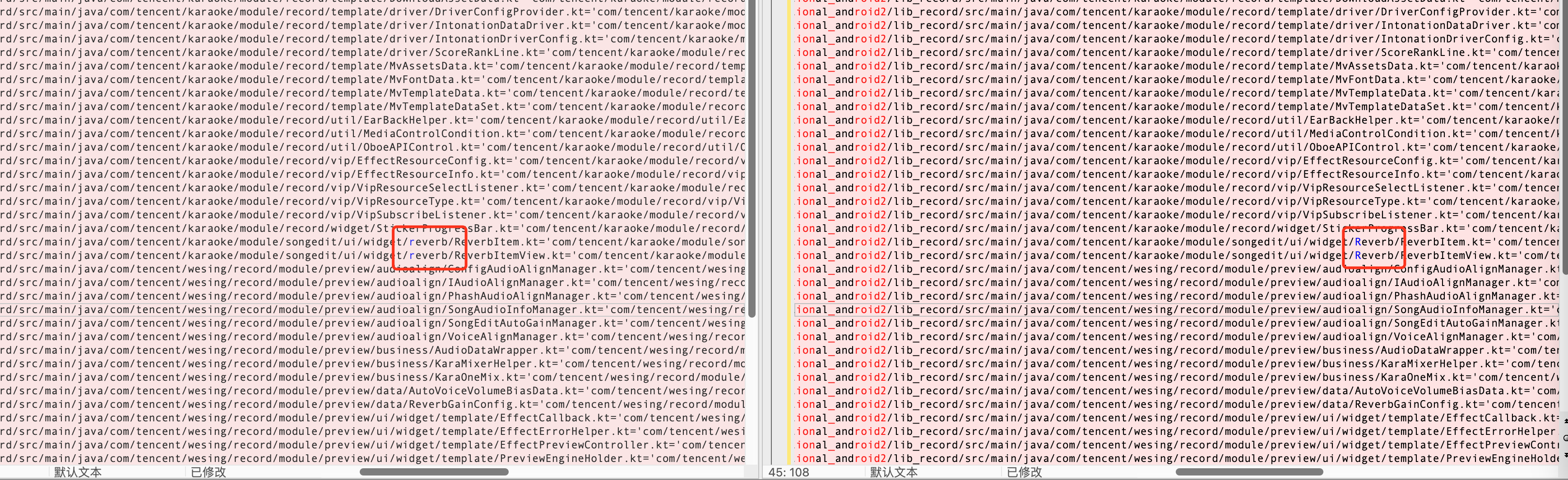
曾经修改过包名的大小写,导致两边构建的参数不完全一致。这里比较坑,因为在大小写不敏感的系统(如 MacOS),目录大小写变更是不会随着 git 更新而更新的,除非删除目录重新同步。
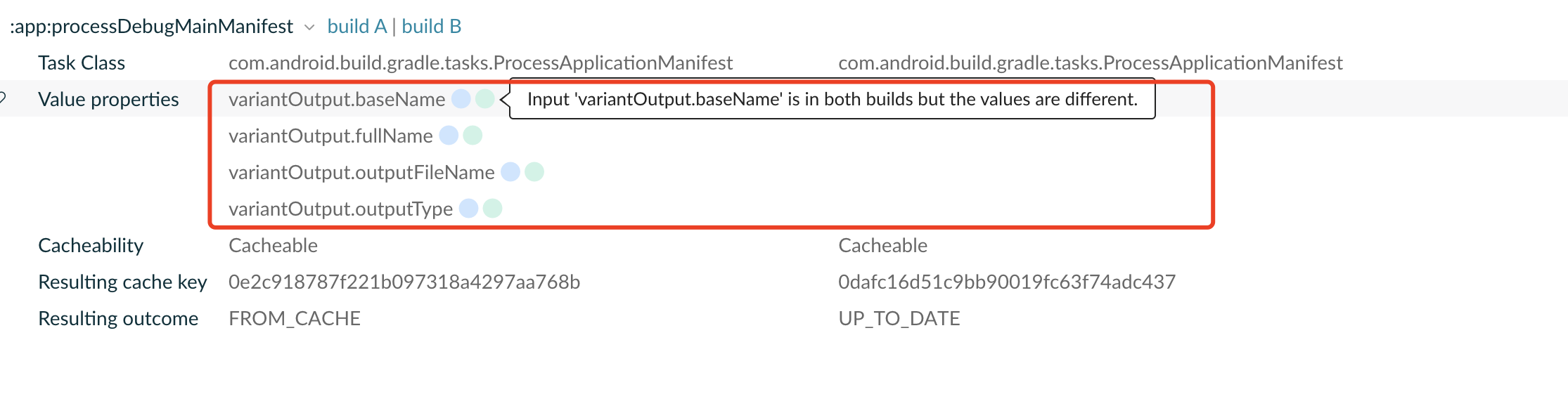
- CI 和本地 split abi 配置不一样,导致 processDebugMainMainfest task 无法缓存。
- 自研/第三方注解器生成代码的结果不稳定。需要排一下序来稳定输出结果。
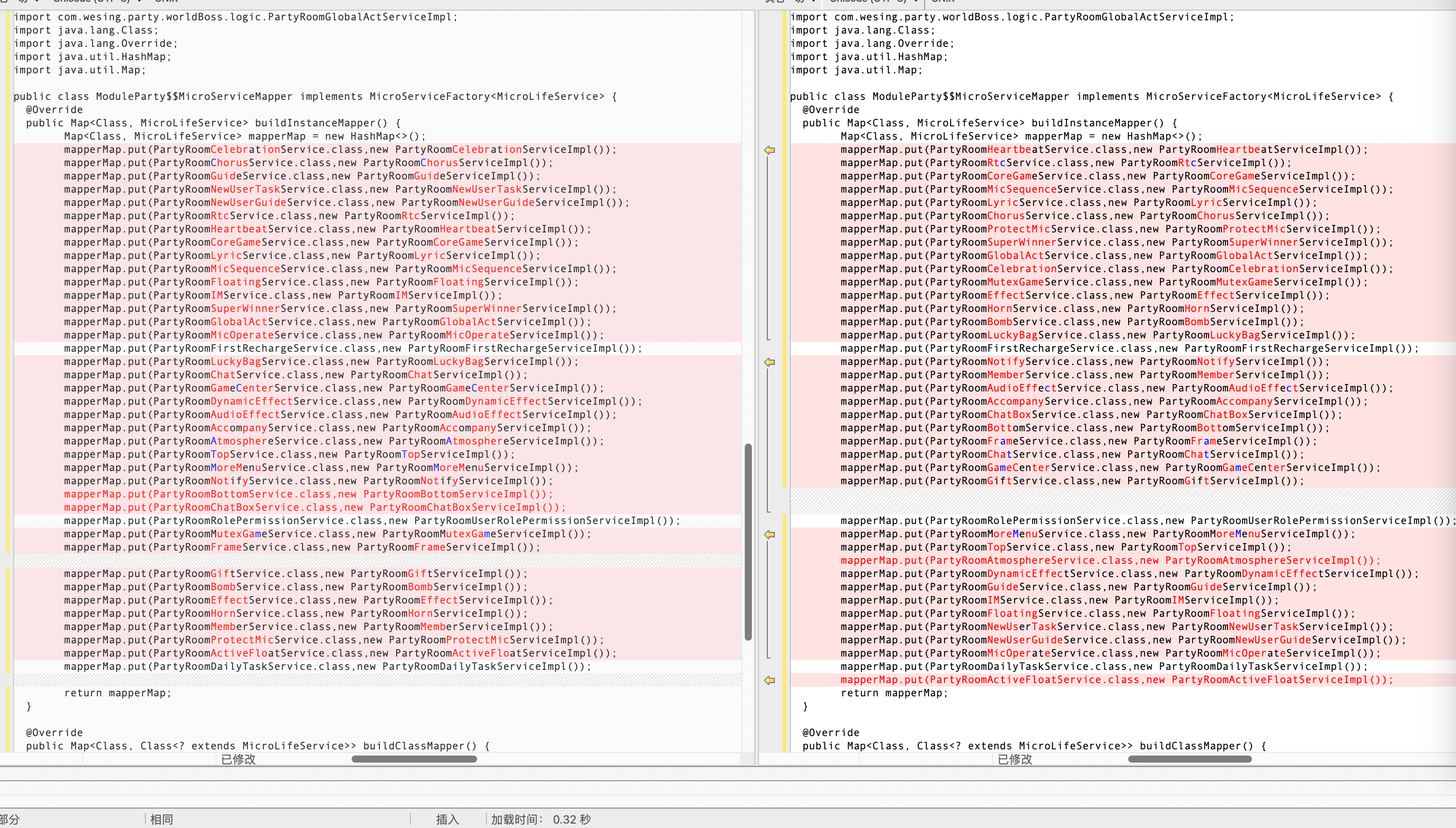
EventBus 也有生成代码乱序的问题,但这个能力是用于加速查找索引的,非开发阶段必须,所以 debug 包可以不执行:

实践效果
在解决了大部分缓存复用的问题后,全新构建从 15min 降低到最低 3min,在大部分主干构建场景下,可节约 80% 以上的构建时间。
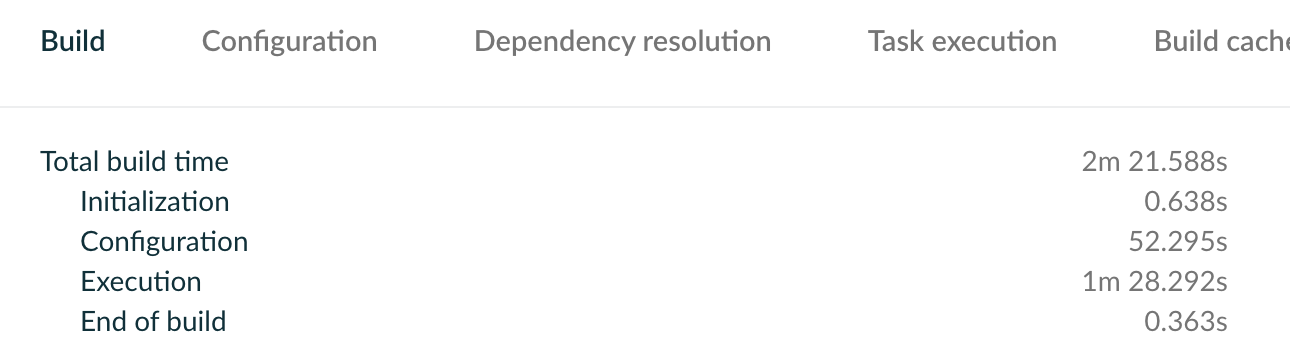
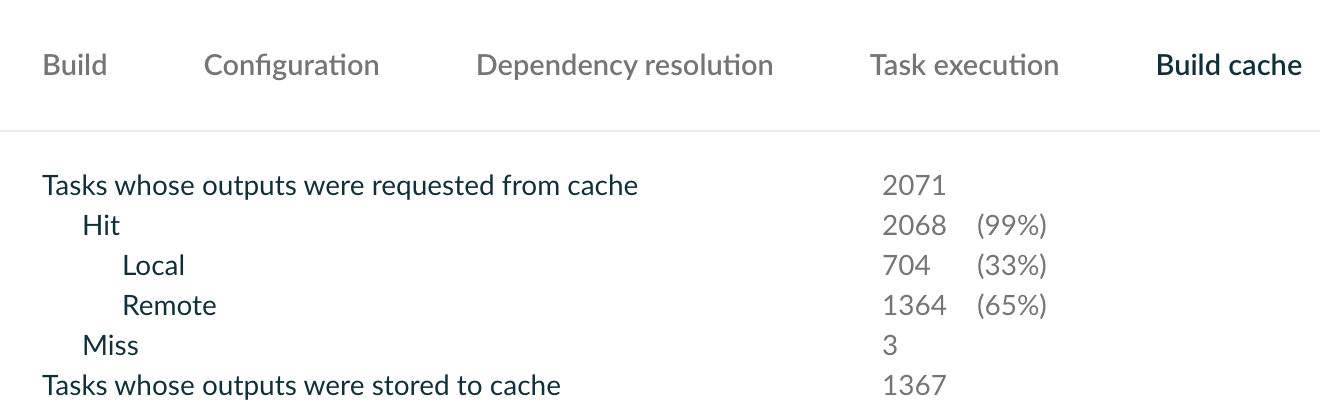
Sickworm 锐评
- 收益:大
- 成本:大(缓存复用是门大学问)
- 综合推荐度:?????(是一个长期有效的解决方案)
6. Gradle configuration cache —— 跳过 configuration 阶段!
Gradle 的执行分为三个阶段: 初始化 Initialization,配置 Configuration,执行 Execution。
- 初始化 Initlaization 阶段:启动 gradle 进程,读取模块列表;
- 配置 Configuration 阶段:创建 task,计算 task 依赖关系;
- 执行 Execution 阶段:执行 task,生成产物。
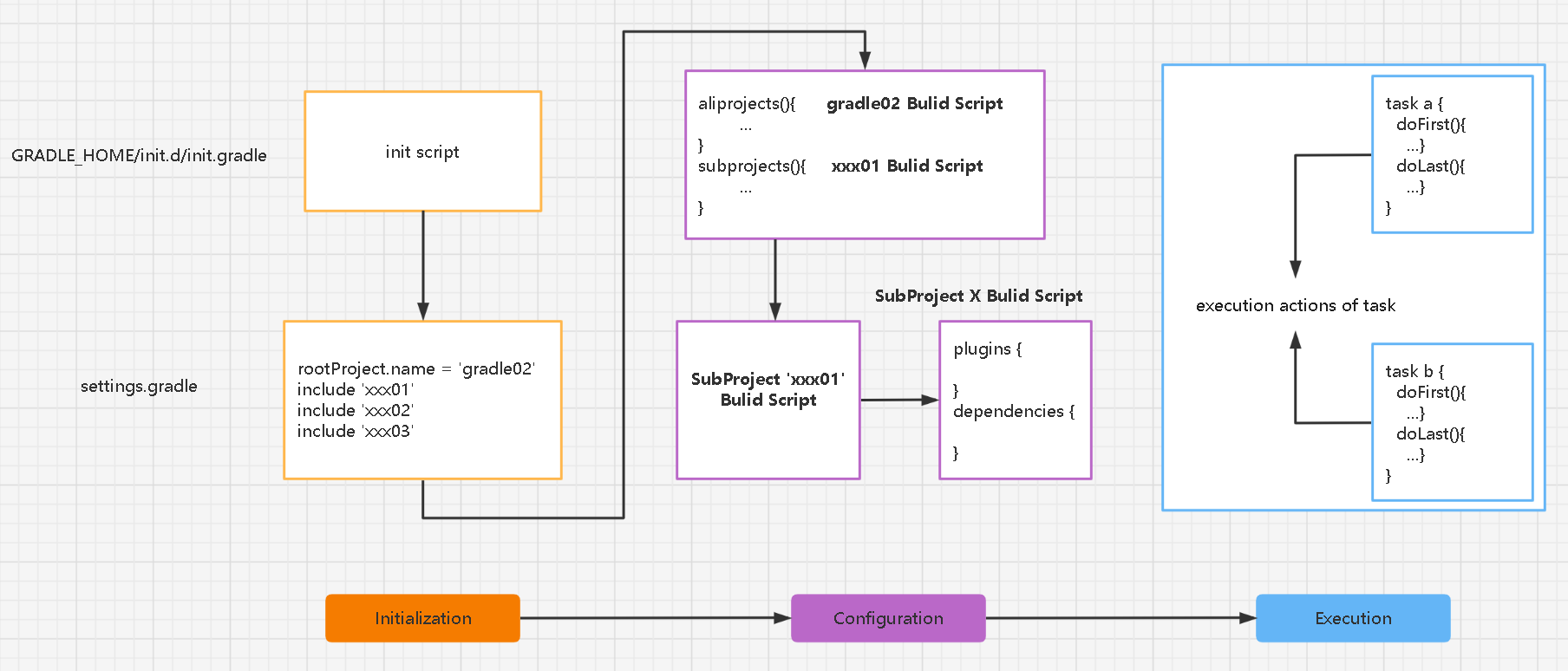
Gradle configuration cache 指的是配置阶段的缓存,当执行过一次某个任务时,下次执行可以跳过配置阶段,直接进入 Execution 阶段。
configuration cache 本质上是将 task 入参,依赖关系等进行持久化存储,下一次运行的时候只要环境变量和执行命令都没有改变,就直接将缓存反序列化,就不用再经过 configuration 阶段执行了。configuration cache 的存储位置为项目根目录的 .gradle/configuration-cache。
实践分享
我所在团队的主工程模块数量达到了 180 个。每次少量修改编译耗时约 60s,但 configuration 就占了 20-30s。 configuration 缓存的实现对我们工程有着非常大的帮助。
configuration cache 打开方式是:在 gradle.properties 中声明 org.gradle.unsafe.configuration-cache=true
打开后运行任意 task,运行结束后 gradle 会判断是否可以缓存。如果不能缓存则报错(不影响 task 执行)。
报错可以通过 org.gradle.configuration-cache.problems=warn 来降级为 warn。但不推荐这么做,因为降级后容易出现其他同学提交了劣化的代码而不自知。
在 configuration 缓存上线后的一段时间内,我遭遇了非常多次背刺。有些同学发现自己写的一些 task 无法复用缓存,然后就会将缓存关闭然后提交到主干。痛苦了一段时间后,最后我通过增加 MR 检查,校验缓存是否关闭,和是否可以成功复用,来保障功能的安全。
官方介绍:Configuration cache
适配 configuration cache
上面提到,打开 configuration cache 后,gradle 会把有问题的地方的报错出来并给出理由,直到所有问题解决。我们只需要一个个修复就可以了。
这里列举大部分场景可能出现的报错,方便大家评估适配工作量:
- Class
XXXX: read system property ‘YYYY’
原因是执行过程中读取了环境变量。
值得注意的是,只有读取存在的环境变量才会报错,如果脚本有读取环境变量逻辑,但实际上该环境变量不存在,则可以成功缓存。
- Class
org.jetbrains.kotlin.com.intellij.openapi.util.SystemInfoRt: read system property ‘sun.arch.data.model’
原因是 Kotlin 未完全适配 configuration cache。 但这个只在首次编译会出现一次,第二次就消失了,所以可以不管。
据说升级到 Kotlin 1.5 可以解决,但我这边工程已经是 1.7 还是可以偶尔报错,可能是依赖版本没有清理干净。
- invocation of ‘Task.project’ at execution time is unsupported.
原因是 task 执行期间引用了 project 对象,导致无法缓存 configuration。
task 也分为初始化阶段和执行阶段,我们需要在 task 创建时,把需要的变量存储并声明为 @Input,从而实现执行阶段访问 project 对象。
- Task
:app:compressImagesof typecom.tencent.karoke.ImageCompressionTask: cannot serialize object of type ‘java.util.concurrent.ThreadPoolExecutor’, a subtype of ‘java.util.concurrent.Executor’, as these are not supported with the configuration cache.
原因是 task 的变量无法被序列化 ,导致无法缓存 configuration。需要保证 task 的参数都是可以序列化的。
Sickworm 锐评
- 收益:中
- 成本:大(自定义 task 越多工作量越大,还需要第三方插件也支持)
- 综合推荐度:????(模块越多收益越大)
7. Maven 网络请求优化
Gradle 会在 Sync 和 Configuration 的时候,请求 Maven 仓库下载未下载的依赖库,或检查是否有更新。
正常情况下,Gradle 会正确运行,不会有不合理的请求。但不正常才是正常,如果:
- 你的工程里有 SNAPSHOT 库,且 SNAPSHOT 超时时间设置的不合理;
- 声明了一个不存在的依赖库版本(并不一定会导致你编译失败);
- 依赖库版本使用了 + 号(有新用新);
那么 Gradle 执行过程中,就会有不必要的网络请求。多的时候,每次编译可能都要花费 10s 以上时间去做不必要的网络请求。(Offline Mode 可以解决此问题但开开关关也麻烦)
网络请求优化的整套方案,包括检查,修复,防裂化的方案可以直接参考:gradle sync阶段依赖库耗时治理和防劣化
此外,减少不必要的 maven 库引入,和调整 maven 库顺序,来提高查找命中率,也可以有效地优化首次下载的耗时。
Sickworm 锐评
- 收益:中
- 成本:小
- 综合推荐度:?????(很正,很值得投入的一个优化)
8. 模块源码 aar 动态切换 —— 牺牲正确性换取减少大量的 task 执行
模块数量会导致 configuration 阶段耗时增加,和编译 task 增多。应避免过度增加 gradle 模块。
如果你的工程已经有很多模块了,可以考虑源码 aar 切换方案。方案大致如下:
- 为模块计算 checksum;
- CI 创建一条流水线,为每个模块打包 aar;
- 本地开发时,自动或手动选择源码还是 aar。手动就是搞个开关,自动就是本地算出 checksum,然后查询是否有匹配的 aar,如果有则使用。
此方案优点:
- 大部分时候我们对不开发的模块都不关心,所以绝大部分模块都会切成 aar,所以编译耗时大大减小;
此方案缺点:
- 如果你升级了一个库,这个库有 API 变更影响了其他模块,那么你会收获一个 RuntimeException。而如果要做到智能识别,那方案就会开始做的很重;至于影响主干和线上倒是不用担心,保证源码编译就可以了。
- checksum 检查可能计算耗时很长,最终收益反而不明显。这里比较考验方案设计能力;
- 这个方案定制程度很高,大概率很难做成可以打包给其他团队的功能;
实践经验分享
暂时没有投入。全民 K 歌团队有一个不错的实践:Android全量编译加速方案
Sickworm 锐评
- 收益:大
- 成本:大
- 综合推荐度:???(双刃剑)
9. android.enableJetifier=false
Jetifier 是 Android 官方用来将 support 库迁移到 AndroidX 库的工具。
Jetifier 已内置到 AGP(Android Gradle Plugin)。通过声明android.enableJetifier=true,AGP 会把你所有的依赖库都转换一遍,保证不会留下 support 库依赖。
Jetifier 有一定耗时,主要在下载新依赖库时需要进行一次转换。关闭 Jetifier 可以减少 Sync 和编译耗时。
大家可能看过一篇比较火的文章:哔哩哔哩 Android 同步优化•Jetifier,里面 Sync 耗时 10 分钟挺吓人的。但其实开发场景遇不到,因为就算你 clean 了 project,gradle 也有缓存的 jetified 产物。
所以这个操作在本地开发基本是增量的,只有库版本更新的时候才需要真正执行,耗时不高。如果是无缓存构建会对耗时一定优化。
实践经验分享
工作量主要分三部分:
- 可以升级的库安排升级;
- 升级也不支持的库,且实际没有,用
exclude group干掉。(jetified 工具会告诉你没有需要转换的 API) - 升级也不支持的库,需要用工具手动 jetified,手动维护它和它的依赖包,且每次升级后还要再来一次。
如何扫描需要转换的库
选择 Migrate to AndroidX,IDE 会扫描出来。 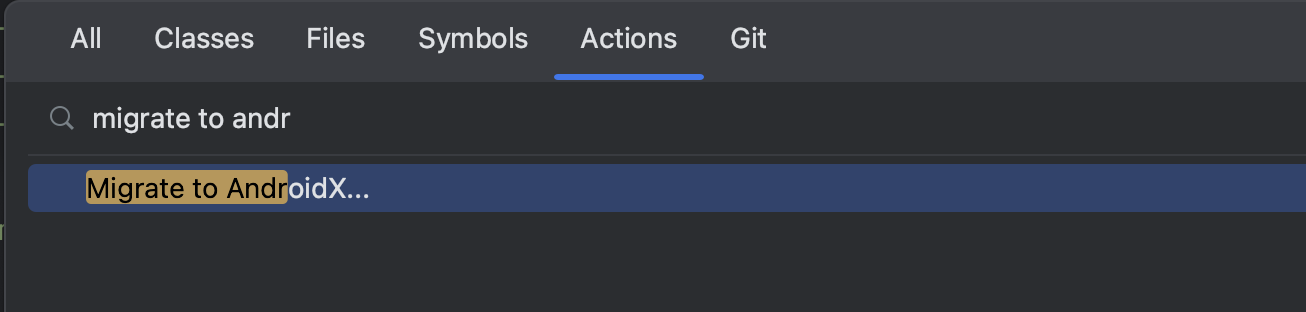
如果存在未清理的 support 库,则会因为重复类而报错。(特别需要注意:你的工程依赖没有主动 exclude support 库,否则就检查不出来了)
如何进行转换和上传
通过 maven-publish 插件编写上传脚本,或 maven 命令行手动上传到内部仓库。
Sickworm 锐评
- 收益:中,落地后发现对大盘编译耗时没有影响,但对 build cache 复用有帮助。
- 成本:大。
- 综合推荐度:???
10. com.android.build.gradle.internal.dependency.AndroidXDependencyCheck$AndroidXEnabledJetifierDisabled_issue_reported=true
也是 Bilbili 文章提到的一个参数,关闭 jetifier 的检查。
看起来是蚊子肉,不太有感觉(你进来了吗?)。
Sickworm 锐评
- 收益:小
- 成本:小
- 综合推荐度:??
11. android.nonTransitiveRClass=true
Transitive R Classes 指的是:如果模块 A 依赖模块 B,那么你可以用模块 A 的 R 类,直接引用模块 B 的 资源(资源具有传递性)。
那么 Non-Transitive R Classes 指的是:模块 A 要引用模块 B 的资源,需要用 B 的 R 类来访问(因为都叫 R,这时候通常就需要指定 B 类 R 的完整类名)
Non-Transitive R Classes 对于大工程好处:
- 降低
generateDebugRFile耗时。传递性 R 会触发所有依赖模块的 R 文件生成 task。
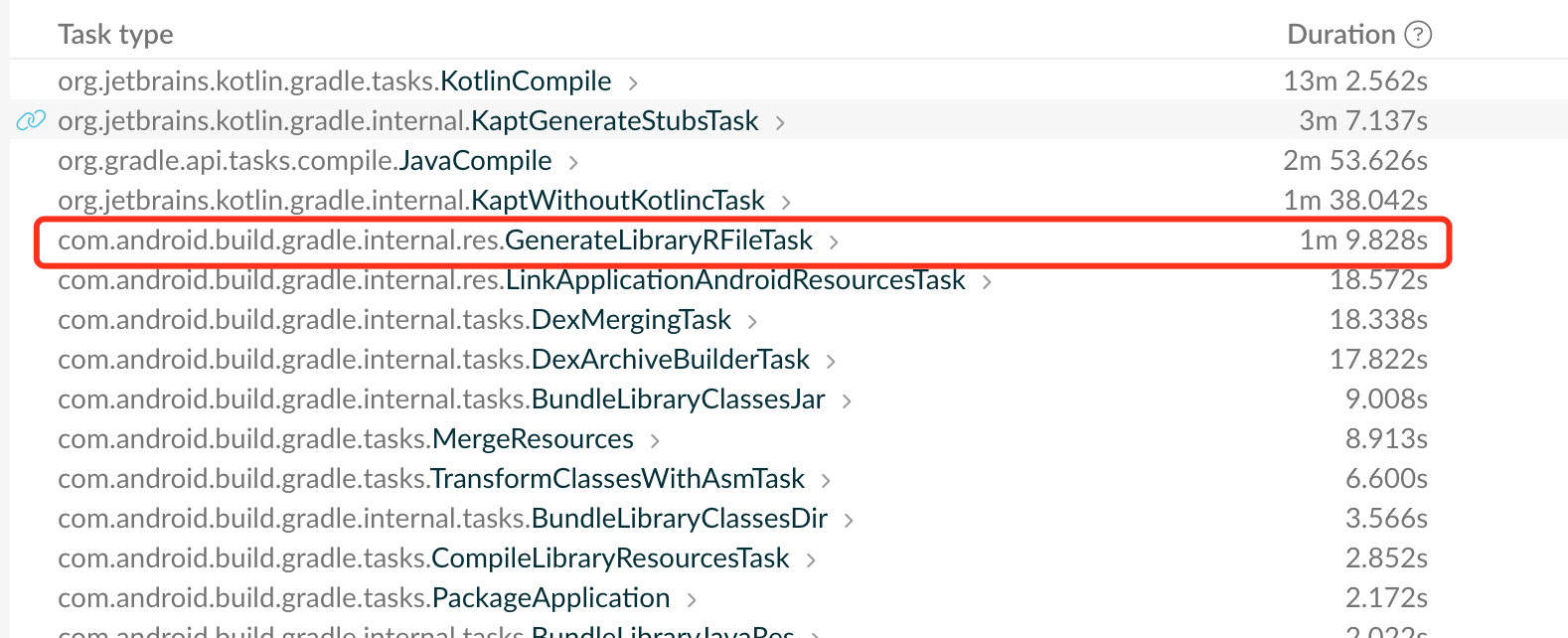
- 可以减包。在我们的产品上 R 类占了包体积 7-8MB,不过我们用 r-inline 插桩去掉了。
实践经验分享
还没做,等刷 OKR 的时候再做吧。
Sickworm 锐评
- 收益:中。可减少
generateDebugRFile的编译耗时,和部分compileJava和compileKotlin的编译避免(一个模块增加了资源 ID,R 文件的变化不会再穿透到其他模块)。 - 成本:大。主要是改动非常大,必须一次性处理完,代码合入的时候也会很痛苦。Android Studio 提供了迁移工具,但据说不够聪明。但值得庆幸的是,未修复的编译会报错,不用担心漏到线上。
- 综合推荐度:????
12. 设置合理的 gradle JVM 参数 —— org.gradle.jvmargs
org.gradle.jvmargs 用于指定 gradle 进程的 JVM 参数,可以指定 JVM 初始堆内存大小,和最大堆内存大小等。
kotlin.daemon.jvm.options 用于指定 Kotlin 编译器守护进程的大小。
举例:org.gradle.jvmargs=-Xmx4096M -Dkotlin.daemon.jvm.options\="-Xmx4096M" -XX\:+UseParallelGC
这里的参数配置是:
- gradle 最大堆内存 4096M
- Kotlin 编译器守护进程堆内存 4096M
- 使用并发 GC 回收实现(官方推荐)
设置过小的最大内存可能导致 OOM;设置过大的最大内存会使你的编译环境变得很卡。我们团队的工程曾经因为构建 release 包 OOM,把两个最大内存都改到了 8G,结果导致平时开发变得很卡。
所以这里也建议分开维护 CI 构建和本地开发的 org.gradle.jvmargs 参数。方式有两种:
- 运行 gradle 前替换
gradle.properties的内容; - 运行 gradle 时增加命令行参数,如:
-Dorg.gradle.jvmargs="-Xmx8192M -Dkotlin.daemon.jvm.options\\=\"-Xmx8192M\""。
13. 技巧——修复 Could not connect to Kotlin compile daemon
如果你感觉这次编译突然变慢了很多,而且出现了 Could not connect to Kotlin compile daemon,那么说明 Kotlin 编译器的守护进程挂了(猜测是 OOM 导致)。失去了守护进程的 Kotlin 没有了复用能力,Kotlin 编译会慢很多倍。
这个时候取消编译重新跑一次,会比你老实等待编译完成更快。
Sickworm 锐评
- 收益:大
- 成本:小
- 综合推荐度:?????(Nothing to loss, right?)
14. kotlin 增量编译 kotlin.incremental.useClasspathSnapshot=true
这个参数据说可以增快 40% Kotlin 1.7 的编译速度(A new approach to incremental compilation)。
但我加到工程里之后,编译耗时大盘均值基本没有波动。
不仅如此,后面在复用 CI 缓存的时候发现这个参数还导致 CI 的 task 缓存和本地编译的 task 缓存无法复用。遂弃之。
Sickworm 锐评
- 收益:负
- 成本:无
- 综合推荐度:这很难评
15. 一些其他的,一般都已经打开的的编译参数
kapt.incremental.apt=true
开启 kapt 增量编译,需要 kapt 注解器支持。未发现副作用。
org.gradle.configureondemand=true
按需 configuration 模块。如果一个 task 不需要所有模块执行,那就不配置所有模块。未发现副作用。
org.gradle.daemon=true
复用 gradle 进程,复用的情况下,编译可以快约 30%。
但无论开关,Android Studio 都会开启一个常驻进程。
但还是建议开启,因为对云编译有效。
org.gradle.parallel=true
并行执行 task。未发现副作用。
结尾
感谢阅读,欢迎交流!