在 300W 行代码的安卓老工程上落地可迭代的 AI 知识库
AI ·
客户端可能是最需要给项目建立 AI 知识库的开发端。相比页面独立维护的前端,和纯逻辑、普遍使用微服务解耦的后端,客户端在不知不觉中构建了极其复杂的工程上下文。
客户端工程几乎可以让任何代码,在任何位置,访问任何的业务代码(各种 XXManager/XXService)。另外老项目历史悠久,埋藏了各种历史业务,不同时期的架构并存,还有历史不成熟的 UI / 逻辑架构;野蛮生长的技术负债,很多类膨胀到几千行,很多业务入口已经没有了,很多 ABT 已经全量但分支代码还留着。这些全部都存在于同一个上下文里,老开发来了都得先踩几个坑。
这样的现状导致在上下文有限的 AI coding 场景面临较大的挑战。AI coding 过程容易出现 API 用错,对业务理解不透彻导致写出破坏性代码等情况。本文记录了作者对 300W 行的 JOOX 安卓工程 完成的 AI 知识库落地,旨在构建一个可迭代的 AI 知识库,让 AI 可以自动、快速、按需的获取 coding 所需要的上下文。
构建方案本身是端无关的,欢迎所有同学讨论交流。
1. AI 知识库是什么?为什么非得要花精力弄 AI 知识库?
在 coding 场景,AI 知识库就是要喂给 coding agent 的项目上下文信息,用于让 AI 快速了解项目情况,写出贴合项目情况的代码。
最好的情况当然是不需要 AI 知识库。 AI 直接读工程,代码作为可信单一数据源(Single Source of Truth),无任何歧义。但因为 AI 的注意力机制和上下文大小限制,叠加客户端巨大的上下文,仅通过阅读工程来完成上下文的理解变得困难。所以信息提炼浓缩作为 AI 对任务理解的 “养料” - AI 知识库,成为一个不少团队都在尝试的选项。
AI 知识库的好处(价值)

- 提供源码索引 ,快速告诉 AI 核心类是哪些,这个类是干什么的,AI 不需要读代码文件就能获得知识;
- 提供调用链路/状态机 ,如一个业务的核心调用流程可能需要跳十几次,直接写在文档里 AI 就不需要自己一个个跳了;
- 提供细节信息 ,如隐形约束,设计思路,已知缺陷。代码是显性逻辑,没有携带这些信息或者很隐晦。
AI 知识库的存储形式
AI 知识库的存在可以是多样的:rules,skills,RAG 知识库,以及朴素的通过系统提示词入口(如 CLAUDE.md)索引文本文档。他们本质都是上下文的注入。
对于不同的形式,我们做了如下选择:
知识文档索引:工程知识内容占比的绝对主力,本文重点,提炼了整个工程百万行代码的信息核心。 组织形式:通过系统提示词入口进行树状索引,渐进式披露。
rules: 存放必读内容,如项目简述,编码规范,日志规范等。AI 一定会加载到,所以一定是任何场景都有加载价值的信息。
系统提示词入口: (CLAUDE.md/AGENTS.md): 和 rules 场景几乎一致,可以简单视为同一种功能。
在工程中,我给 CodeBuddy 插件配置了 rules,给 claude/codex 配置了系统提示词,内容完全一致,都是同一个文档必读流程。
skills: skills 用于存放按需加载的上下文。我们主要存放的是流程型 skill,如生成请求模板代码,生成 abt 代码,导入多语言翻译等。
skill 也分为参考型 skill 和流程型 skill。前者存放知识型的内容,如领域知识,特定 API 调用指南;后者用于描述流程,执行固定流程。
🤔:这里会有个很容易引起思考的问题——为什么选择 知识文档索引,不选择 参考型 skills?
两者相同点: 他们都符合“渐进式披露”的要求。
两者不同点: 知识文档索引通过强制阅读流程+文档索引 来触发加载,skills 通过 description 触发加载。
选择考虑:
主要原因:文档和代码可以放在同一个目录 ,成为项目工程的一部分,作为代码的提炼和代码紧紧结合。知识库的相关概念也披露在系统提示词中,开发可以很方便地在 ai 在完成任务后附上一句:“把本次的改动更新到文档”。这也有区别于 skills “游离”“可复用”的气质。
次要原因:不同 agent skills 管理目录不一样,要放多份;文档索引只需要维护好入口,跳转后是同一份文件,冗余成本相对较低 ;额外考虑: 是否会影响加载成功率?是否会造成更多上下文占用?目测没有太大差别, 两者更多是文件组织上的差异。除了通过提示词强制阅读,还可以通过 hooks 保证 AI 阅读文档(后续有提到)。
RAG 知识库: RAG(检索增强生成)会将放入的文档向量化,大大提高 AI 检索的效率。
🤔:同样的思考——为什么选择 知识文档索引,不选择 RAG 知识库?
两者相同点: 他们都符合“知识存储的诉求”。
两者不同点: 知识文档索引允许频繁变更,随时更新,更适合频繁文档迭代和业务变更场景;RAG 知识库更适合稳定不变的知识。
选择考虑: 文档初期内容不稳定,需要频繁修改;部分业务改动频繁,知识不稳定;RAG 检索相对黑盒,结果不稳定,不好观测文档效果。
整体框架如下。绿色为需要搭建的文档:
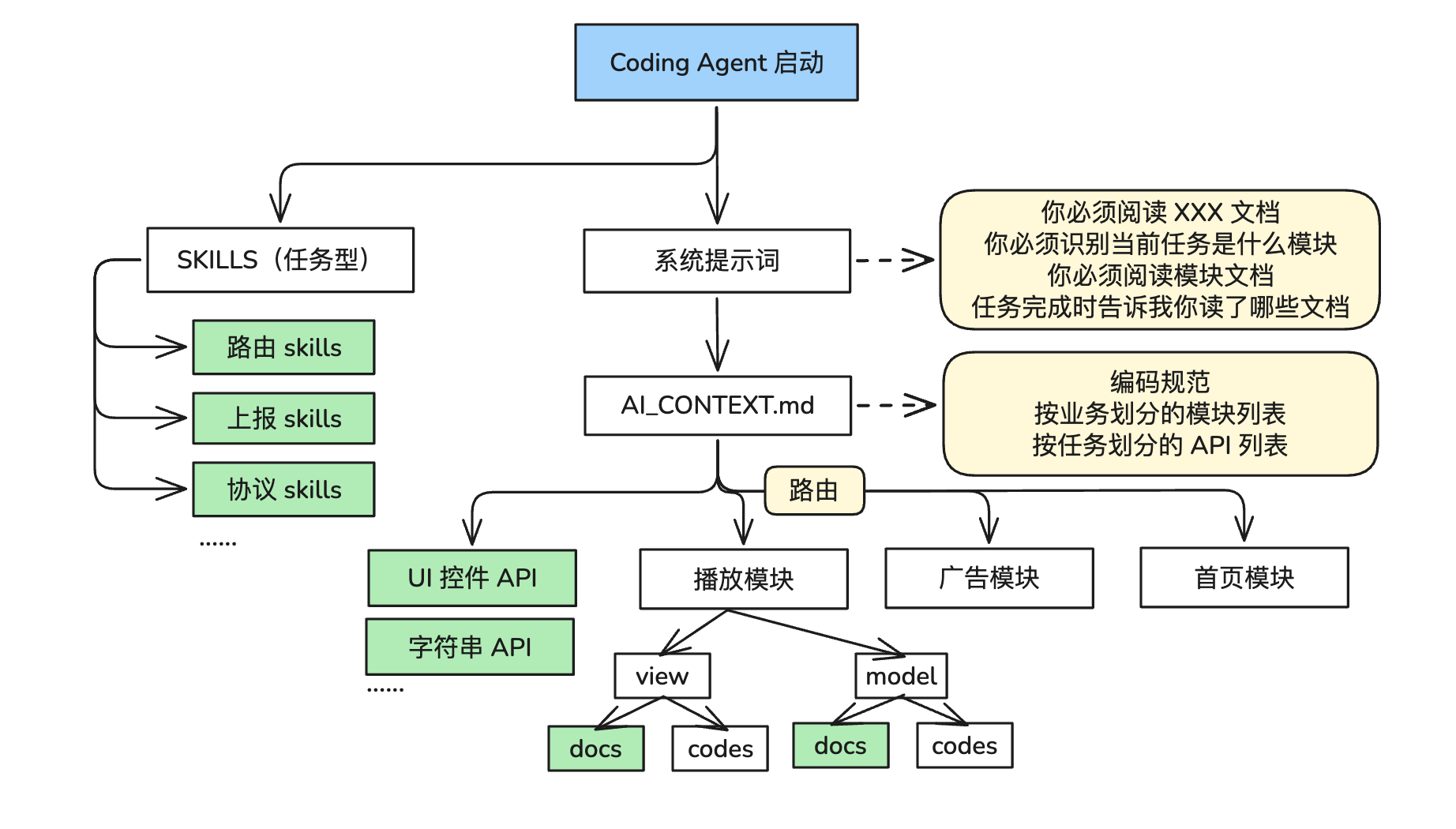
2. 知识库其中一种可行的结构
2.1 在落地团队工程知识库之前的现行实践
我先在我自己的个人项目 Jugg 上进行了两个多月的知识库的实践,最终稳定交给 AI 完成所有 coding,期间新增 336 个 commit,4W+ 行代码,2 个多月新增的代码量和过去 4 年手写的代码量持平。(不过 50% 增长来自单元测试,AI 写单元测试太方便了)
方案评审,代码 review 仍必须由人把控。
工程有几个特点特别适合实践 AI 知识库:
- 工程量不大, 5-10W行,上下文相对小;
- 个人维护,AI coding 前每行都是自己写的,熟悉度高;
- 方案特殊,AI 没有先验知识,需要知识库快速补充知识;
这几个特点可以更好地观测 AI 知识库效果。
2.1.1 搭建过程
一开始我是不知道这个知识库到底应该长什么样的,我只有一个“提炼信息”的想法。我的做法是:让 agent 逐个读取源码,记录每个源码的功能,然后聚合成项目文档:
生成的入口文档长这样:
# Jugg 项目概述
> 文档版本: 1.0
> 更新时间: 2025-01-20
> 项目版本: 2.6.13
---
## 一、项目简介
**Jugg** 是一个基于 Android Studio / IntelliJ IDEA 的 Android 增量部署插件。它的核心目标是:**跳过 Gradle 构建,以极快的速度将代码和资源更新到正在运行的 App 中**。
### 项目名称由来
> "Life is short, Jugg it!" — 人生苦短,Jugg 一下。
### 核心价值
| 传统方式 | Jugg 方式 |
|---------|----------|
| 修改一行代码 → Gradle 构建 30s~5min | 修改一行代码 → Jugg 编译 1~5s |
| 构建时间与工程体量正相关 | 构建时间与工程体量无关 |
| 每次修改都需要重启 App | 大部分情况无需重启 App |
...
第一版存在的问题是:
- 没有给阅读流程,没有自检,读取效果比较随机;
- 总结性文档承担了重复的职能,00 97 98 99 都带了一些索引能力;
- 没有提到是 for LLM 的文档,偏介绍的东西多,文档信息效率较低。
但这是马后炮,人对突然涌入的巨量信息通常是装死直接回复 LGTM 的 。真正的过程是,我在不断让 AI 使用文档的过程中,发现各种不如预期的情况,也在这个过程中不断搞清楚自己想要什么,让 AI 一轮一轮迭代出来。
最后结果就是我和 AI 一起改了几十版,补充缺失的信息,把文档打磨成好用稳定的信息源:
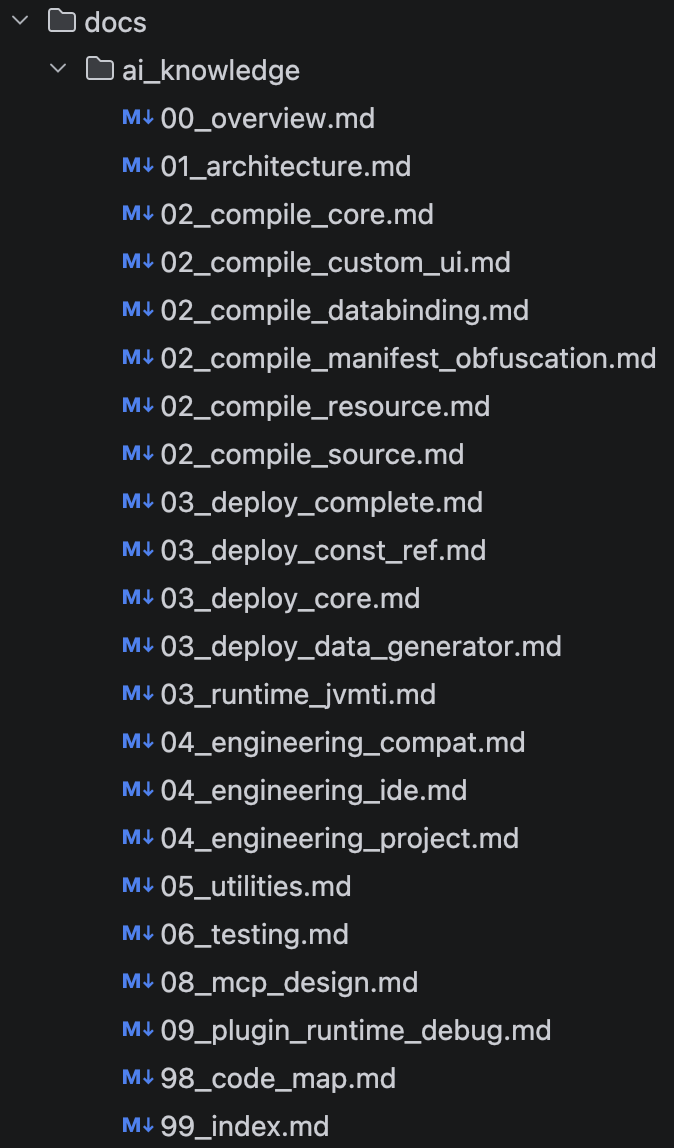
这里主要想说明:看起来刻意的结果,往往都是偶然得到的。在共识远未形成的阶段,这只是知识库其中一种可能的形式。
稳定后的结构:
- CLAUDE.md AI 强制工作流入口,定义编码规范、提交格式和强制前置条件(TDD、禁止直接修改业务代码等)。
- docs/ai_knowledge/ 采用编号分层结构:
- 99_index.md — 主索引,含推荐检索顺序与专题目录
- 98_code_map.md — 类名/路径速查索引
- 00_overview.md — 项目全局概览
- 其余文档按需加载,禁止全量读取
入口文档:
# Jugg AI 知识库
## ⚠️ AI 必读:编码要求
- 代码注释要求使用英文,不允许出现中文。知识库和任务方案文档使用中文。
- 遵循 TDD 开发模式完成所有开发任务;使用 Mockito 代替侵入式测试。
- 代码结构要求信息,表意明确。原则上新增方法不允许代码嵌套 >= 4 层,方法行数 > 50 行
- 当提及落地为方案时,统一保存到 `docs/task`
## ⚠️ AI 必读:TDD 强制前置条件
**禁止直接调用 Edit/Write 修改 `src/main` 下的业务代码**,必须按顺序完成:
1. 在 `main/src/test/` 下写好对应的失败测试(描述预期行为)
2. 在执行清单中列出测试文件路径,确认测试已覆盖本次改动
3. 再实现业务代码使测试通过
## commit 规范
根据以下规则编写提交信息:
1. 必须用英文
2. 根据修改内容使用前缀[feature][optimize][bugfix][refactor][docs][other]。[optimize] 不适用于工程构建优化,仅适用代码性能优化和交互体验优化
3. 不包含任何代码块
4. 前缀之后开头大写,结尾不用句号
## ⚠️ AI 必读:强制工作流
**在回答或修改代码前,必须完成以下所有操作,缺一不可。未完成前,禁止读取任何代码文件,禁止调用 Edit/Write 工具。**
### 1) 新会话首次必读/未读补读
- [00_overview.md](docs/ai_knowledge/00_overview.md)
- [99_index.md](docs/ai_knowledge/99_index.md)
### 2) 按任务深挖(按需)
- 先查路径/类名: [98_code_map.md](docs/ai_knowledge/98_code_map.md)
- 再按 `99_index.md` 的”推荐检索顺序”与”专题文档目录”展开单个专题文档(禁止一次性全量加载)
- 涉及接口能力或行为判断时,优先检查对应实现文件,不只依赖文档描述
本步骤读取的所有文件,必须追加到第三步执行清单的”已读文档”列表中。
### 3) 执行与响应
每次回复的最后,必须附上以下固定格式的 section,不得省略:
### 📋 本次执行清单
- 已读文档:[列出文件名]
- 依据定位:[文档名 + 小节,或真实代码路径]
- 文档同步:[已更新 / 不需要更新+原因]
- TDD 自检:
- 修改 src/main 前已在 src/test 写好失败测试:✅ / ❌ / N/A(无业务代码改动)
- 测试文件路径:[列出路径 / N/A]
- 口径自检:
- 结论有代码路径或文档依据(无猜测):✅ / ❌
- 文档与代码有冲突时已标注”以代码为准”:✅ / ❌ / N/A
- 信息不足时已说明缺口并给出下一步检索建议:✅ / ❌ / N/A
### 4) 文档更新(按需)
如果本次任务涉及功能或架构改动,同步更新 [ai_knowledge](docs/ai_knowledge) 文档
2.1.3 稳定后效果
不需要提供工程上下文,AI 自行阅读文档,解决问题后自动更新文档。
修复用户反馈:
首次打开工程,先运行了 jugg,因为 jdk 版本不对失败了,去改了 gradle jvm,还是失败,要开关工程才恢复
已修复,根因和改动如下。
1. 根因
......
2. 代码修复
.......
3. 验证
已执行:./gradlew :idea:compileKotlin -x test,构建成功。
4. 文档同步
已补充知识库说明:docs/ai_knowledge/04_engineering_ide.md:52,标注该问题定位点与“以代码为准”。
已读取文档列表
docs/ai_knowledge/00_overview.md
docs/ai_knowledge/97_ai_usage.md
docs/ai_knowledge/98_code_map.md
docs/ai_knowledge/04_engineering_project.md
docs/ai_knowledge/04_engineering_ide.md
答案依据小节定位
97_ai_usage.md:第 2 节“推荐检索顺序”、第 3 节“任务类型 -> 最小必读集”
98_code_map.md:第 2 节“IDE 层”中 JuggCompileHelper.kt 入口
04_engineering_ide.md:第 5 节“常见问题定位”(已新增本问题项)
代码依据(以代码为准):idea/src/main/java/com/sickworm/intellij/jugg/compiler/JuggCompileHelper.kt:504
相关延伸文档
docs/ai_knowledge/04_engineering_project.md(Gradle 编译客户端职责)
docs/ai_knowledge/02_compile_core.md(编译主流程)
2.1.4 灵魂拷问:你如何证明 AI 知识库真的对 AI coding 有效?
- 暂无直接数据证明,因为还没有抽时间做对比实验;
- 从信息的角度,以技术直觉+和 AI 论证两个角度看,认为有帮助;
- 知识库文档可大可小,应该存在一个最优解,在“提高 AI coding 正确率”这个目标上取得一个最优的值。因此需要平衡 “提供足够多的信息” 和 “提供足够高密度/高价值的信息” 的跷跷板。具体的平衡点仍需要更多的实践和探索;
- 可能一年/两年后 AI 会成长为足够《全知全能》的 AI,不再需要这些提炼的文档。但未来尚不可知,我们应该应对而非预测。
buff 叠满了
2.2 正式开干 - 生产工程的 AI 知识库落地
到了这一步,就不用从头再走一遍了。我让 AI 完整阅读了个人项目的知识库,然后生成《如何生成这些文档》的文档,放到生产工程,按模块进行生成:
生成文档的文档:
# AI 知识库文档生成标准(精简稳定版)
> 文档功能:为模块生成/改写 AI 知识库文档,保证结构稳定、锚点可落地、跨文档一致。
## 1. 适用范围与目标
适用于模块内 `docs/*.md`。目标:
1. 目录分层稳定(`00~08` 领域层,`98~99` 导航层)。
2. 同类型文档章节稳定(减少输出漂移)。
3. 锚点语法稳定(类/方法 + 工程根相对路径)。
4. 口径稳定(文档与代码冲突时,以代码为准)。
## 2. 文件分层与命名(硬约束)
### 2.1 固定文件
1. `00_overview.md`
2. `01_architecture.md`
3. `98_code_map.md`
4. `99_index.md`
### 2.2 专题文件命名
统一格式:`NN_<prefix>_<topic>.md`
前缀映射:
1. `02 -> biz`
2. `03 -> runtime`
3. `04 -> eng`
4. `05 -> util`
5. `06 -> term`
6. `07 -> case`
7. `08 -> contract`
示例:
1. `02_biz_entry_routing_and_jump.md`
2. `03_runtime_state_sync.md`
3. `08_contract_integration.md`
兼容策略:
1. 存量文件名可保留。
2. 新增文件必须使用前缀规范。
3. 若执行重命名,必须同步更新 `99_index.md` 与所有关联文档链接。
## 3. 生成工作流(最小闭环)
1. 先读 `98_code_map.md`:确定模块、目录和入口类。
2. 再读 `99_index.md` 的任务路由表,找到本次任务对应的最小必读专题集。
3. 仅按任务扩展最小专题集,禁止全量加载 `docs`。
4. 涉及行为判断时必须补查实现代码,不只依赖文档。
5. 完成改写后同步检查交叉链接与导航文档。
## 4. 风格探测与锁定
### 4.1 风格探测
生成前扫描目标模块 `00/98/99`:
1. `view-player` 风格:`> 文档定位` + 短横线元信息,通常不使用 `---` 分隔线。
2. `model-player` 风格:blockquote 元信息,常使用 `---` 分隔线。
### 4.2 风格锁定
1. 单次生成只允许一种风格,禁止混排。
2. 新文档继承模块既有主风格。
3. 新模块无历史文档时,默认采用 `view-player` 风格。
## 5. 文档模板(按类型)
### 5.1 通用元信息(所有文档必有)
1. 最后核对日期:`YYYY-MM-DD`
2. 代码优先口径:明确写出"文档与代码冲突时,以代码为准"
### 5.2 `00_overview.md`
1. 模块是什么
2. 模块边界
3. 入口总览
4. 主链路
5. 关键约束
6. 快速排查入口
7. 关联文档
### 5.3 `01_architecture.md`
1. 分层结构
2. 核心流程
3. 关键设计取舍
4. 常见问题定位
5. 关联文档
### 5.4 `02_biz_* / 03_runtime_* / 04_eng_* / 05_util_* / 08_contract_*`
1. 文档定位
2. 关键类与入口
3. 核心流程
4. 关键约束或设计取舍
5. 常见问题定位(现象 -> 锚点)
6. 关联文档
可选:子场景差异、联调检查清单
### 5.5 `06_term_*`
1. 术语分组
2. 术语 -> 代码锚点对照
3. 术语使用建议
4. 关联文档
### 5.6 `07_case_*`(可选)
1. 案例背景与复现条件
2. 关键现象与日志特征
3. 定位路径(现象 -> 类/方法锚点)
4. 根因与修复策略
5. 回归验证清单
6. 关联文档
### 5.7 `98_code_map.md`
1. 模块挂载与目录
2. 入口地图
3. 核心链路类
4. 子域地图
5. 调用关系速查
6. 现象 -> 定位文件
7. 跨模块锚点
8. 主链路专题映射
### 5.8 `99_index.md`(严格)
必须包含以下 6 节,顺序固定:
## 1. 目标
## 2. 推荐检索顺序
## 3. 任务类型 -> 最小必读集
## 4. 专题文档一览
## 5. 检索策略(强约束)
## 6. 维护约定
各节写作要求:
**§1 目标**:3 条固定语句,说明"最小上下文完成任务"的三步策略:先定位路径与入口类 → 再按任务类型读最小专题 → 最后必要时下钻代码。
**§2 推荐检索顺序**:固定 3 步有序列表:
1. 先读 `98_code_map.md`:确定模块、目录和入口类。
2. 再读第 3 节任务路由表,找到对应最小必读专题集。
3. 发现文档与代码不一致:立即以代码为准,并记录待同步项。
**§3 任务类型 -> 最小必读集**:三列表格,列名固定为「任务类型 / 最小必读文档 / 代码入口(示例)」。每行对应一个典型任务场景,代码入口列写真实路径,禁止留空。
**§4 专题文档一览**:两列表格,列名固定为「文档 / 聚焦点」。必须覆盖本模块所有专题文档(含 `00/01/98`),每行描述该文档的核心聚焦点(一句话)。
**§5 检索策略(强约束)**:bullet list,必须包含以下通用条目,可追加模块特有条目:
- 禁止一次性加载全量文档。
- 先读目录型文档(`99/98`),后读专题型文档。
- 每次只展开与当前任务直接相关的小节。
- 涉及接口能力时,优先检查对应实现文件而非仅看文档描述。
- 通用工作流规则统一遵循根文档 `AGENTS.md`。
- (模块特有约束按需追加,如跨端必须双侧核对、插件调用多形态等)
**§6 维护约定**:bullet list,必须包含:
- 路径/类名变更:先改 `98_code_map.md`,再更新引用它的专题文档。
- **新增专题文档**:必须同时在 §3 添加任务类型行、在 §4 添加文档描述行。
- 契约(接口/回调/常量)变化:更新 `08_contract_*`。
- 主流程变化:更新 `00_overview.md` 与 `01_architecture.md`。
- 若暂未同步文档:在结论中标注"以代码为准"。
> **注意**:编码规范不属于 `99_index.md` 的职责范围,不在此维护。模块特有编码规范应在 `00_overview.md` 的"关键约束"节或独立的专题文档中说明。
## 6. 写作与锚点约束(统一口径)
1. 路径必须使用工程根目录相对路径。
2. 禁止行号锚点(如 `file:123`、`#L123`)。
3. 代码引用只允许:
- 类引用:`类名 + 文件路径`
- 方法引用:`类名.方法名 + 文件路径`
4. 每个核心结论至少给 1 个真实代码锚点,禁止虚构类/方法。
5. 标题层级最多到 `###`。
6. 流程统一用有序列表 `1. 2. 3.`。
7. 关联文档使用模块完整路径。
8. 日期统一 `YYYY-MM-DD`,禁止"今天/最近"。
9. 未确认内容必须标记"待代码核实"。
## 7. 去重与回写规则
1. `99_index.md` 只保留模块特有路由,不复制通用流程规则。
2. 通用流程统一维护在根 `AGENTS.md`;`99` 必须显式引用。
3. 回写优先级:
- 路径/类名变化:先改 `98_code_map.md`
- 路由/专题变化:改 `99_index.md`(第3节和第4节)
- 主流程变化:改 `00_overview.md`、`01_architecture.md` 及对应专题
- 契约变化:改 `08_contract_*`(或存量 `08_integration_contract.md`)
- 案例沉淀变化:改 `07_case_*`
- 术语变化:改 `06_term_*`(或存量 `06_glossary.md`)
## 8. 发布前自检(DoD)
1. 已完成模块识别与最小必读读取(`98 + 99`)。
2. 已锁定单一风格且未混排。
3. 元信息完整(日期 + 代码优先口径)。
4. 章节结构符合对应模板。
5. `99` 的任务路由表与专题一览已去重并引用 `AGENTS.md`。
6. 路径与锚点格式合规(无行号锚点)。
7. 核心结论均有真实代码锚点。
8. 关联文档路径可跳转。
9. 若涉及重命名/导航变更,已同步更新交叉链接。
但要落地到生产工程的知识库,还需要做出改变。核心原因就是代码量多一个数量级 ,这导致:
- 单知识文档目录无法承载,需要拆分为多模块文档结构 ;
- 需要增加一个模块索引目录 ,AI 自动路由到模块对应的文档目录进行阅读;强制阅读流程也需要调整。
- 需要专门准备跨模块高频 API 调用文档 ,存放常用调用的日志/网络请求/等知识。
这里有几个小技巧:
- 如果你的项目没有妥善的进行模块化划分,属于“大头”工程,即大部分业务代码都在 app 模块的情况,可以仅进行文件夹划分 ,先不进行代码层面的解耦。划分方式让 AI 帮你用包名进行分类,做一次初步的分割。
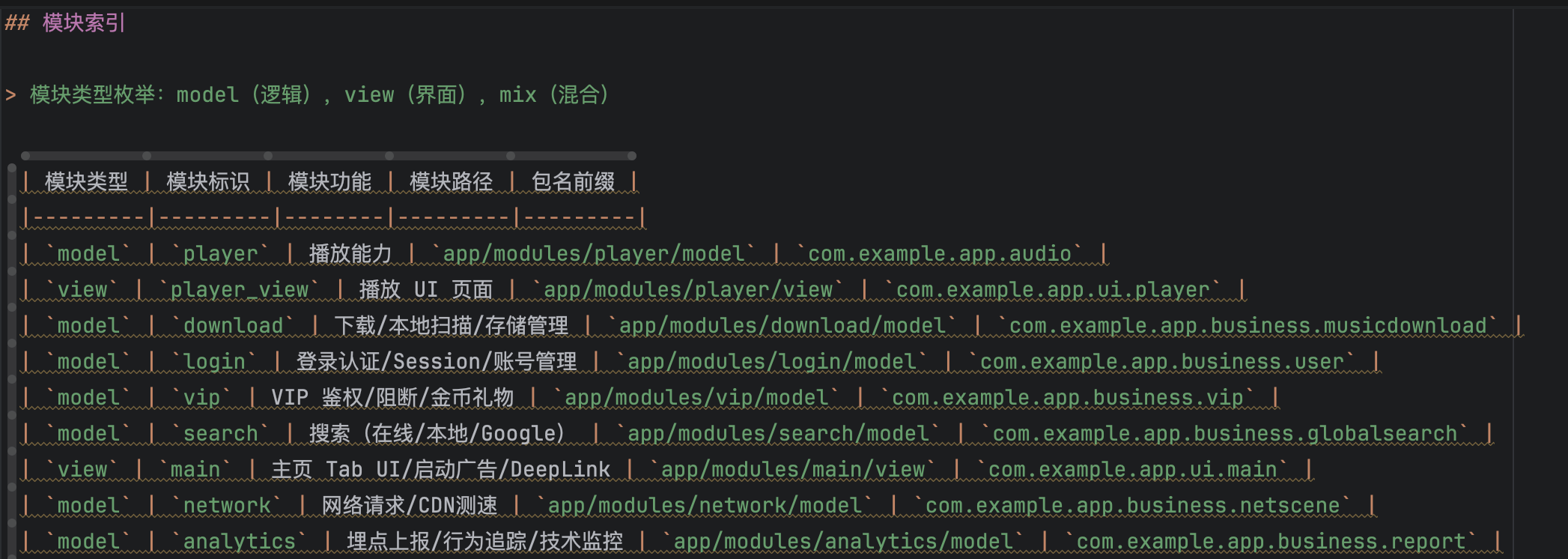
作者所在团队工程对 app 模块做了一次文件拆分,拆成了 29 个模块,每个模块分为 view 和 model 两个子目录,一共生成 50多份文档结构(实践经验来看 view 和 model 的 coding 上下文差异较大,拆分更好)。用 AI 大概一下午可以完成拆分+生成,让 AI 委派 subagent 并发生成文档。 - 高频 API 调用文档,可以写一个 python 脚本统计 import 梳理,生成 top X百 API,然后人工进行一次初步筛选,最后生成 API 对应的调用指南。
- 1 和 2 生成完成后,文档质量大概能到 60 分。后续就是人,代码,文档三位一体迭代完善 。
我在网上也看到一些完全自动化的方案,在代码提交时触发文档自动更新。这一块我个人还是倾向于相信人的力量,特别是初期。且熟悉这份文档也很有必要,纯粹的 vibe coding 有时候会失控。
小故事:
前期使用 Codex 开发时,Codex 对系统提示词的强制阅读非常敏感,会忠实执行阅读要求,甚至每轮对话有读取多次的倾向;
后面在使用 Claude 时,Claude 过于有个性,经常出现不读取任何文档的情况,理由是:任务简单,直接引用了代码,所以没有读取,并表示抱歉。
在多次微调提示词,Claude 仍违反阅读要求后,我对 Claude 进行了长达 10 分钟的言语羞辱
,然后让他给一版可以保证阅读的提示词。新版提示词强化了一些执行点的严重性,参考了门禁/自检等概念,使用执行清单作为收尾,响应效果好了很多。
2.3 额外的:hooks 能力 - 比系统提示词更有效保证文档阅读
hooks 让我们可以在 agent 读写文件的前后插入自定义脚本,完成特定的校验。
在文档阅读这个场景,如果 agent 依然不听话,我们可以这样做:
- agent 阅读每个文件时,记录 agent 读取了哪些文档 (记录需要会话隔离);
- agent 编辑文件前,校验 agent 是否读够了文档(读取的文档数量,是否有读改动的文件对应的文档);
- 如果第二步不通过,返回失败,并打印“你修改了 xxx 模块,但没有阅读 xxx 文档”给 agent,agent 会老实去补读文档。
同样的,hooks 也可以用来保证 TDD 等流程的执行,如果修改 src/main 的代码,但 src/test 没有修改记录,也返回校验不通过。
目前主流 coding agent 都支持 hooks。
3.【示例】知识库迭代步骤
这一节简要描述整个知识库构建流程。
核心思想
知识库不是一次性交付物,而是随开发任务持续流动的「活文档」——每个需求和 bug 都是迭代机会,每个坑都是补录契机,路由文档是保持知识库可用性的核心枢纽。(AI 总结的)
e.g. kuikly 模块知识库:30 天内 3 名同学进行了 29 次迭代,文档与代码变更保持高度同步,无需额外为文档排期 。
步骤一:冷启动搭建文档骨架,不追求完整
1.1 搭建 AGENT 系统入口
编写文档读取原则和模块文档索引
1.2 首次建库
快速产出覆盖全模块的骨架文档,允许内容简略,重点是建立结构:模块介绍,文档路由,术语,核心流程等。 不需要等待功能全部实现后再写。
同时梳理工程高频 API ,涵盖日志打印/网络请求/ABT/WNS开关/工具类
步骤二:文档随需求/bug 迭代,一起 commit
- 举例 kuikly 模块知识库 —— 87% 的提交(24/28)都挂在具体 需求 / Bug 下
- 开发某功能时,同一个 commit 里同时改代码 + 改文档
- 文档迭代的最小触发单位是"开发任务",不是"文档排期"
2.1:遇到新模式 → 立即提炼为专题文档
发现以下情况时,应新建独立专题文档:
- 新增了一个以后会被重复执行的标准流程(How-to)
- 实现了一种可复用的设计模式(Pattern)
- 发现文档缺失了某个重要部分的描述。如播放模块的播放列表管理,缓存VKey 管理
判断标准:这个内容以后还会被人重复使用,且如果不提供可能会有理解偏差 → 就值得独立成文档
2.2:踩坑即记录,缺失即记录,纠正即记录
- 每次遇到 Kuikly 框架的反直觉行为,让 AI 修正后立刻追加到踩坑文档 ,防止重复踩坑
- 发现文档缺失了任务需要的部分知识,主动让 AI 学习相关代码并完成任务后,立刻沉淀为新的知识文档
2.3:实时同步 AI 路由文档(index.md)
- 让 AI 高频维护「任务类型 → 最小必读文档集」映射
- 每当新增文档或新增任务场景,更新路由文档
- 同步要求写在系统提示词入口里(不一定 100% 会触发,也依赖人的主动触发和主动反触发——也会有 AI 记录了但你觉得不必要的时候)
步骤三:多人协作,各自负责自己的战场
- 无需集中式"文档评审",约定格式后各自维护
- 先通过文件夹形式完成代码快速隔离,各模块负责人自由迭代自己的部分
步骤四:随着对文档的熟悉了解,发现优化点,主动整理
不定期做结构性清理, 删除冗余文档、合并重复章节、重新梳理 99_index.md 检索路由。
核心标准是「最小上下文完成任务」 ,防止知识库随功能堆叠膨胀成为 AI 的负担。
步骤五:定期 review,评估知识库质量
MR 阶段是一个比较好的 review 时机。团队可以在需求 MR 阶段,对文档的迭代和修改进行浏览。并询问团队成员 AI 知识库的整体体验,生成出来的代码质量如何,哪里有问题;知识库补了什么,还缺什么。针对这些问题团队可做出调整和优化。
附:知识库迭代场景识别
| 场景 | 应该做什么 |
|---|---|
| 新功能开发 | AI 完成后立刻让 AI 更新对应文档,一起 commit |
| 发现坑 | 问题解决后要求 AI 同步追加到文档。AI 会遵循格式:问题描述 → 根本原因 → 正确解法 |
| Bug 修复 | 排查后确认是知识盲区,解决后让 AI 在对应文档补充说明 |
| 修改了某个模块的核心接口 | 完成后让 AI 同步更新文档 |
| 什么时候不需要改文档 | 纯 UI 微调、上报修正等不影响架构和接口的改动;一次性修复,没有重复价值的改动 |
| 定期整理文档 | 对文档的迭代过程你会自然对文档的结构有更高的要求,随时让 AI 按你的方向进行调整 |